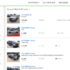
I have a customer who is failing to scrape prices from size.co.uk. They went to the effort of adding our PhantomJS scraper in order to scrape the prices, but are still failing to grab anything from that site. They sent me this image from the debug page of their Price Comparison Pro config.
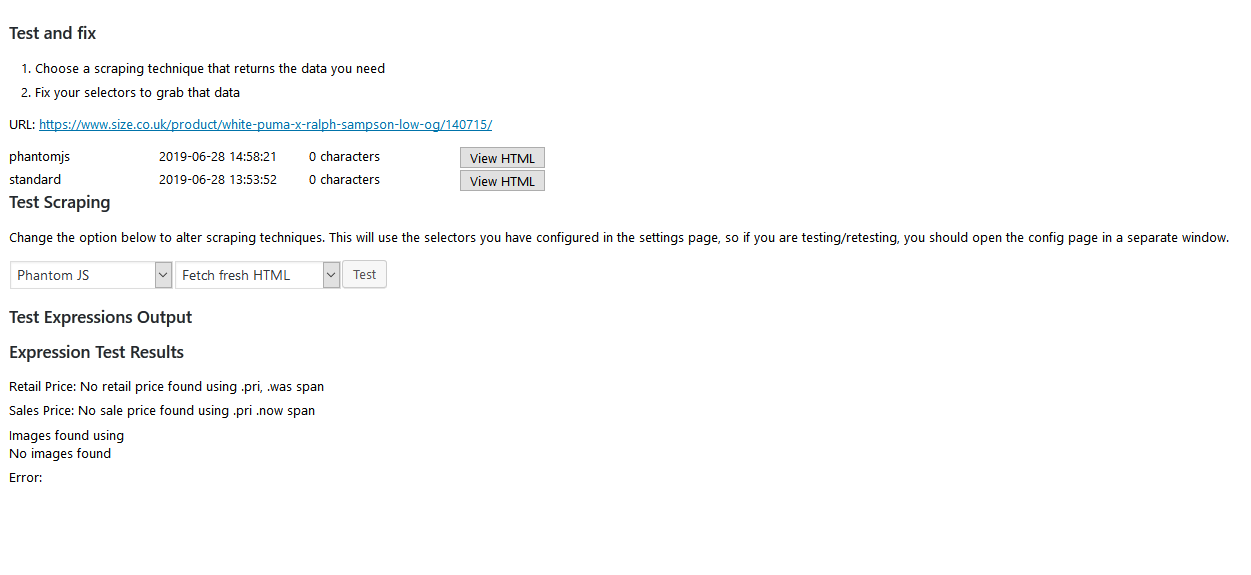
Table of Contents
Analysing why the scrape is failing
You’ll notice above that 0 characters were returned in the scrapes, both when using ‘standard’ and when using ‘phantomjs’. This indicates one of two potential issues:
You may not have cURL enabled on your hosting. cURL is required in order to scrape pages, so you need to check this is available and activated in your php.ini file. To enable it, add the following to your php.ini file:
allow_url_fopen = On
If that is not the solution, then you should check the HTTP STATUS returned by the scrapes. In Price Comparison Pro you can see this from the Debugging page where it should ideally show an HTTP status of 200 (meaning success).
Note: It’s possible that Price Comparison Pro shows an HTTP status of -1 which means it grabbed that HTML from the cache.
So, if you have an HTTP status of something other than 200, or -1, then you probably have been blocked by botblockers. These will ban your site from scraping if you try to scrape too many pages in too short a time.
The most likely HTTP status code if you have been banned is the 403 forbidden status code. You can find all HTTP status codes here.
Getting around bot blockers with Price Comparison Pro
Price Comparison Pro has multiple solutions for this – inside the plugin you will find a link to purchase proxies and a link to get a Scraper API subscription.
Proxies work by passing your scrape request through a different IP address. With Price Comparison Pro you can add as many proxies as you wish and then the plugin will rotate through those IP addresses. So, if you add 10 proxies, you will be able to scrape 10 times more than normal before being banned. If you add 100 proxies, you will be able to scrape 100 times more than normal before being banned.
For proxies, we recommend My Private Proxies for reliability and price. There is a link inside our plugin to these guys too. With multiple proxies, you can then either use the ‘standard proxied’ or ‘phantom js proxied’ scraping approach. The standard proxied will use a random proxy from your own server (fastest) whilst the phantom js proxied will use a random proxy through our own scraping service. You should only use our scraping service when you need to scrape a site which puts prices on the page using Ajax.
Alternatively, you can use the third-party Scraper API service. They automatically rotate the proxies for you, and they even provide a ‘rendered’ option which is similar to our phantom js scraping service – i.e. their rendered scrapes (slower than standard) will run javascript on the page before passing back the fully rendered HTML. Again, you should only use rendered if the page you are scraping is using Ajax.
How to tell if Ajax is being used or if selectors are wrong
The example page this client is trying to scrape is from size.co.uk for a pair of Puma trainers. The specific link is:
https://www.size.co.uk/product/white-puma-x-ralph-sampson-low-og/140715/
By visiting that page, I can visually confirm the price of the trainers is £80.00.
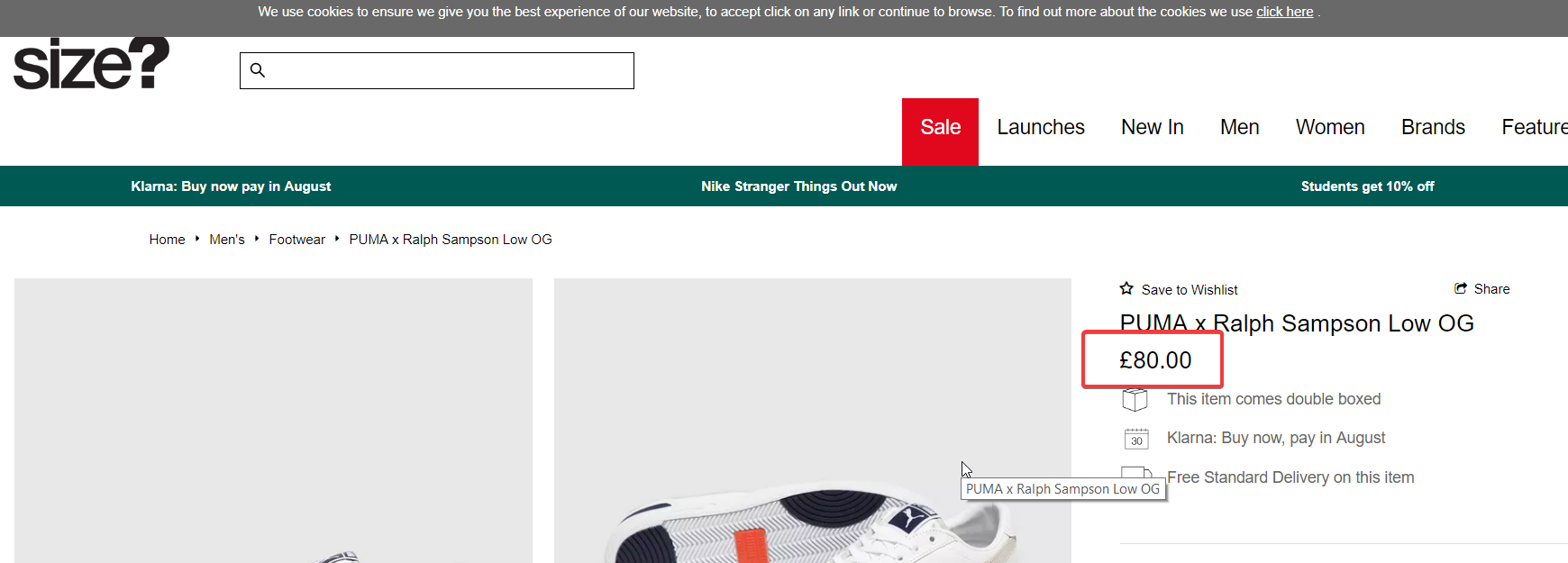
By right clicking the price, then choosing Inspect Element, I can see the raw HTML. Note: when using Inspect Element you are viewing the rendered HTML i.e. this is the HTML after JavaScript has run. Still, this inspect-element tells us the correct CSS selector to use.
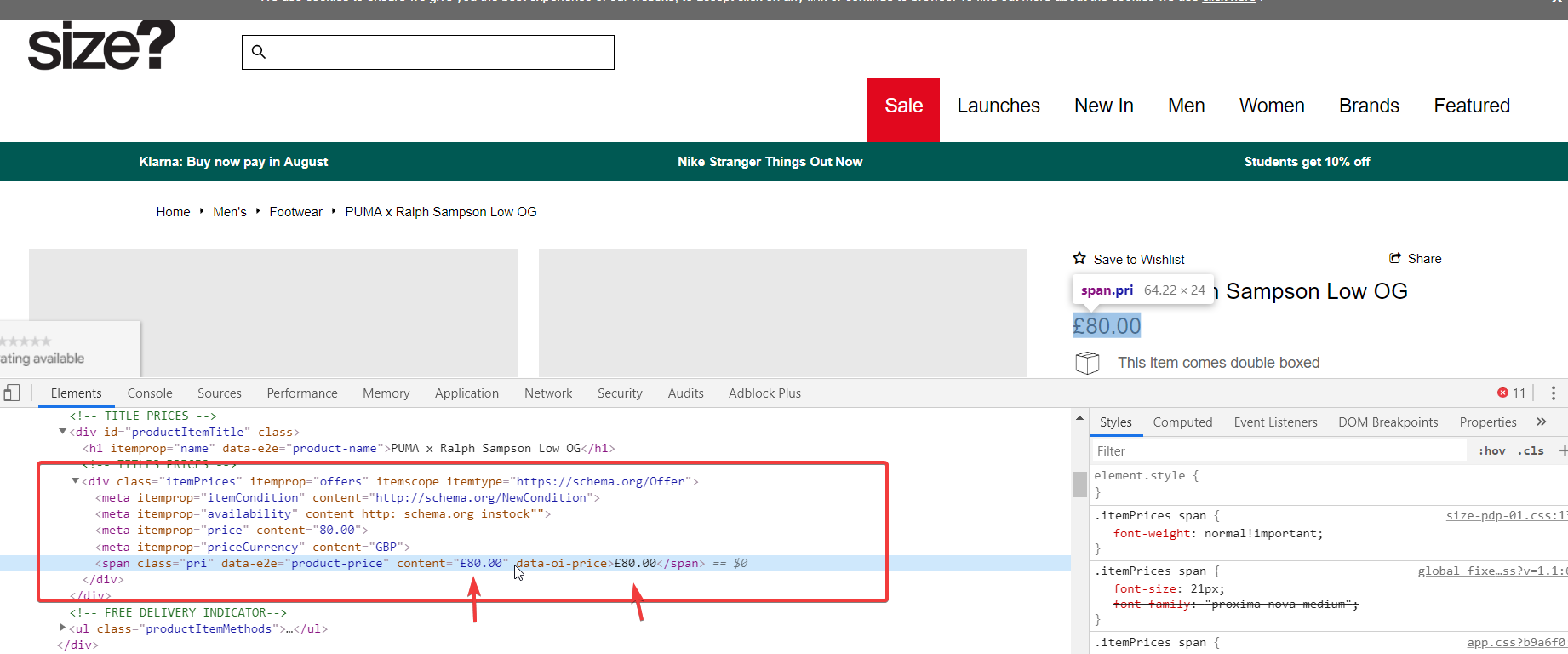
I’ve covered grabbing the correct CSS selectors or xPath selectors in a separate knowledge base article, so I won’t go into detail here except to confirm that .pri is enough to grab the price here when there is no sale on.
Remember, you should normally have two selectors for the retail price – one for when there’s no sale on and the other for when there is a sale on. Typically the retail price will have a strikethrough through it when the product is on sale. You just separate the selectors by commas in the config screen for Price Comparison Pro and the plugin will try them in order.
I can see from the config that this user has it correct – they are using: .pri, .was span – this means try finding a price with the class of “pri” followed by trying to find a price with class of “was” and then the span inside that element.
Ok – so to check if the price is added using Ajax, we need to view the page source. This is different from Inspect Element since viewing the page source shows us only the initial HTML that is returned to the browser. So, we’ll view source then search for 80.00 and check if the surrounding HTML is similar to what we saw with Inspect Element.
In Chrome, to view source, just hit CTRL+U or CMD+U. Other browsers differ slightly but all have this capability.
Here is what I found when I viewed source for this page then searched for 80.00 – I had to continue to the 5th match of 9 to find the related HTML.
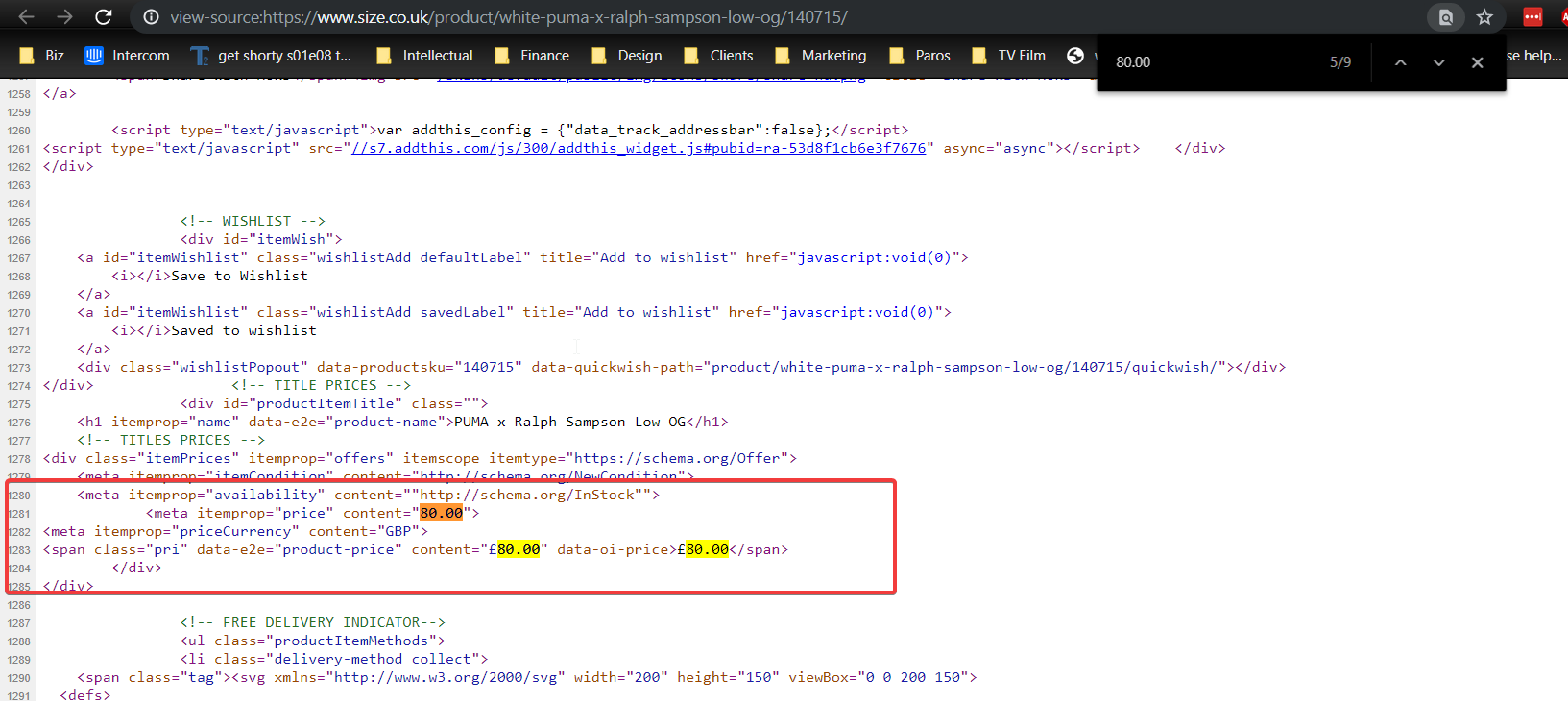
So – that tells us that the raw page source includes the price and Ajax is not used to insert the prices on this page. That means, we can rule out Ajax as a problem here and it means we can use any of the standard scraping techniques to scrape prices from this site.
Testing scraping of the size.co.uk site
I added the config for www.size.co.uk to my FoundThru demo site and created a new page with a PcPro shortcode on it. Here’s the site config:

It’s fairly basic, I didn’t bother adding a logo URL for this test or anything. I then used this shortcode:
[pricecomparisonpro urls="https://www.size.co.uk/product/white-puma-x-ralph-sampson-low-og/140715/" affiliateurls="https://www.size.co.uk/product/white-puma-x-ralph-sampson-low-og/140715/" displaystyle="panel"]
I added this shortcode to this URL here:
https://foundthru.com/demo-scraping-size-co-uk/
Now, I can see that I’m having the same exact issue the client is having when trying to scrape size.co.uk – see image:
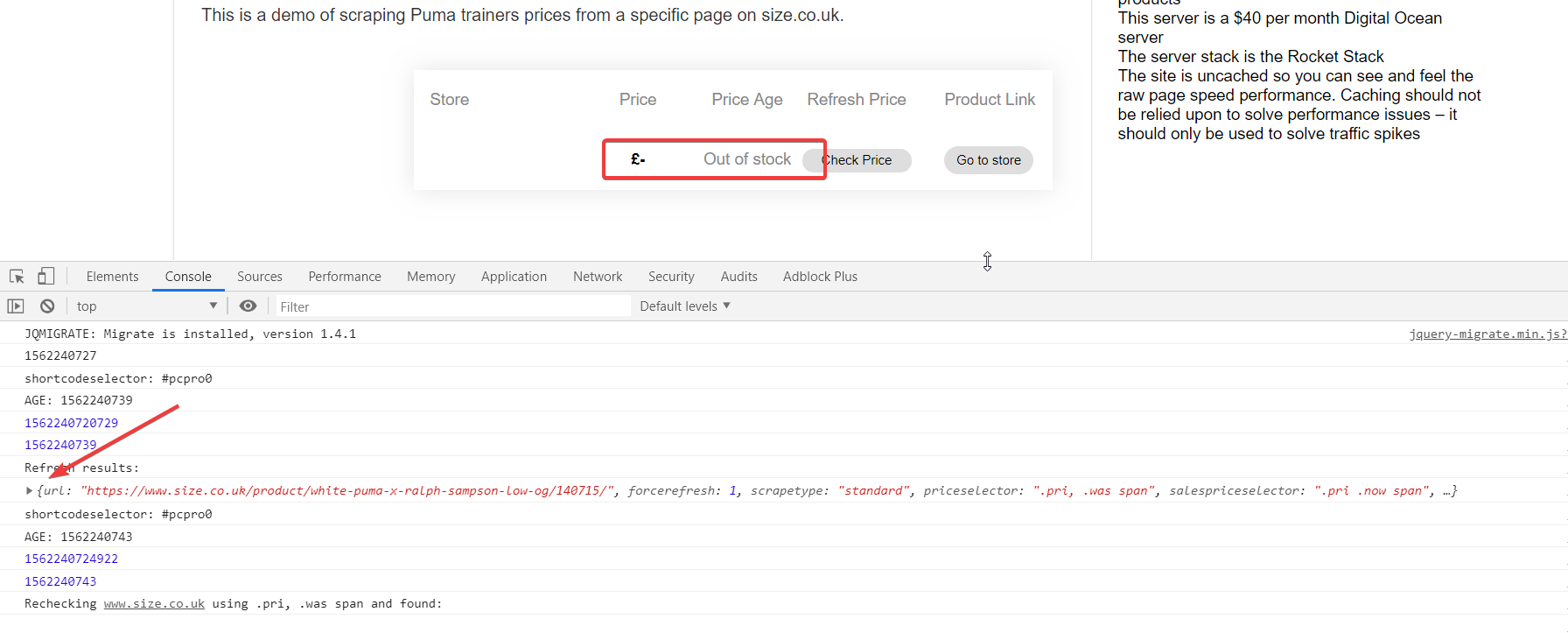
The arrow in the image above is available if you open the JavaScript console and then click the ‘Refresh’ button on the Price Comparison Pro panel. This is what is displayed when I use this debug technique:
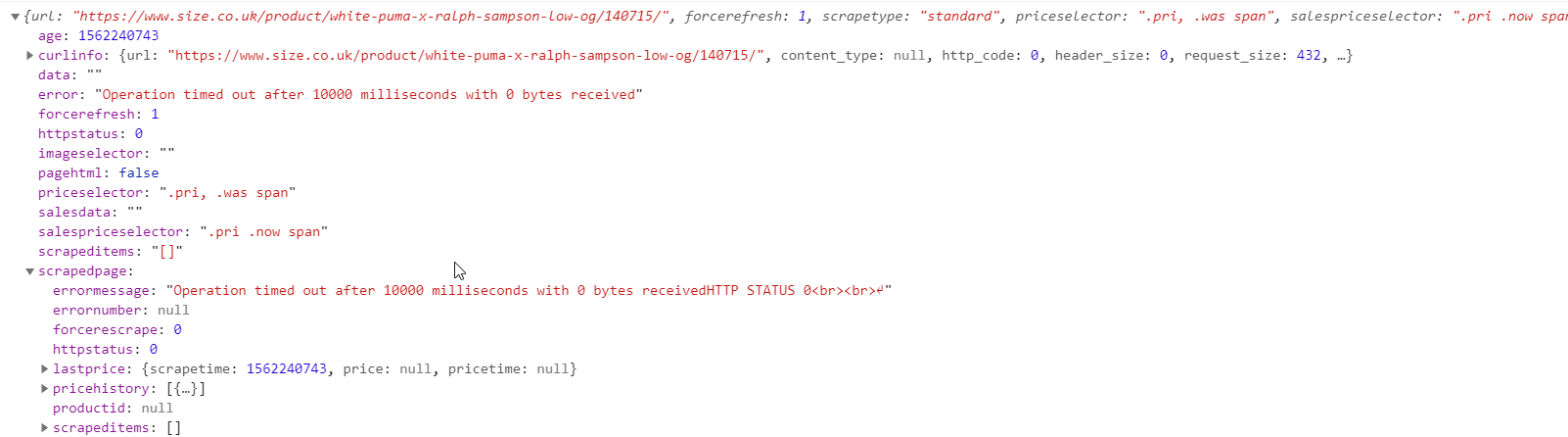
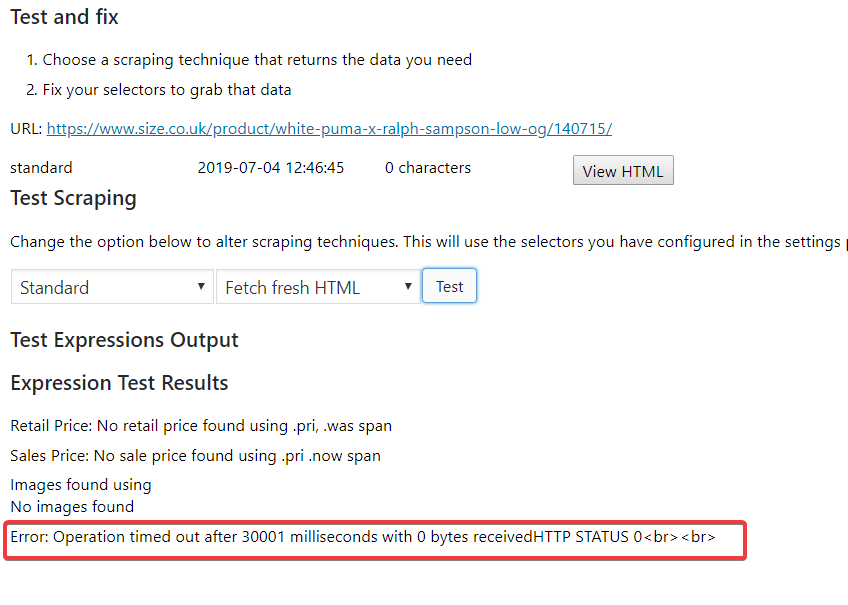
So – we can see that the error is: Operation timed out after 10000 milliseconds with 0 bytes received. That’s why we’re seeing an HTTP status of 0. Another way of viewing this debug is from the backend where in Price Comparison Pro -> Debug & logging we can see output like this:

When I click ‘test scraping’ and then try to scrape again, I got the same error of a timeout as I’d seen from the front end.
Fixing the timeout issue
10 seconds really should be long enough for HTML to be returned, but currently there’s no way of reconfiguring this in Price Comparison Pro, so in order to figure this out I’m going to go into the code and manually alter this timeout to see if I can actually force a scrape to happen here. The other alternative is to use the Scraper API since there is a longer timeout on their service since it’s effectively going through a proxy.
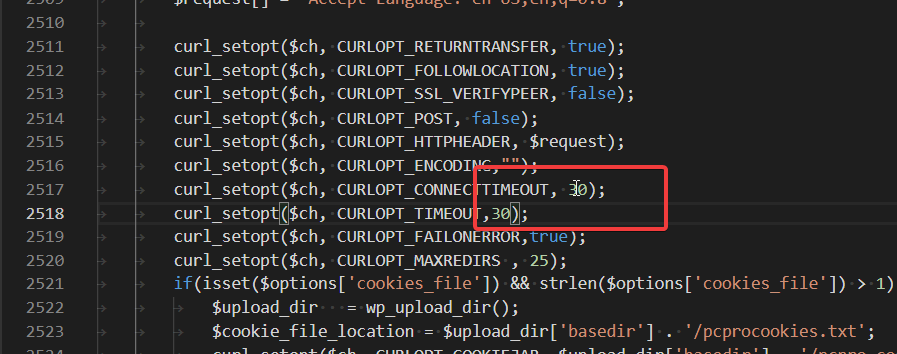
Results with 30 second timeout
Unfortunately, with the timeout increased to 30 seconds, I’m still seeing a timeout. That means that this website is somehow blocking our cURL request. Presumably they’re doing something like setting a cookie then refreshing the page then looking for that cookie on the next page load. It’s how I blocked password-bots to my site in the past.
Testing with proxies
It could be possible that the foundthru site has been added to a blacklist somewhere and the IP address is blocked. So – we should test using proxies to confirm this. I already have proxies set up at Foundthru for a select few sites, so to test this in the debug page I can just alter the scraping type and try scraping again:
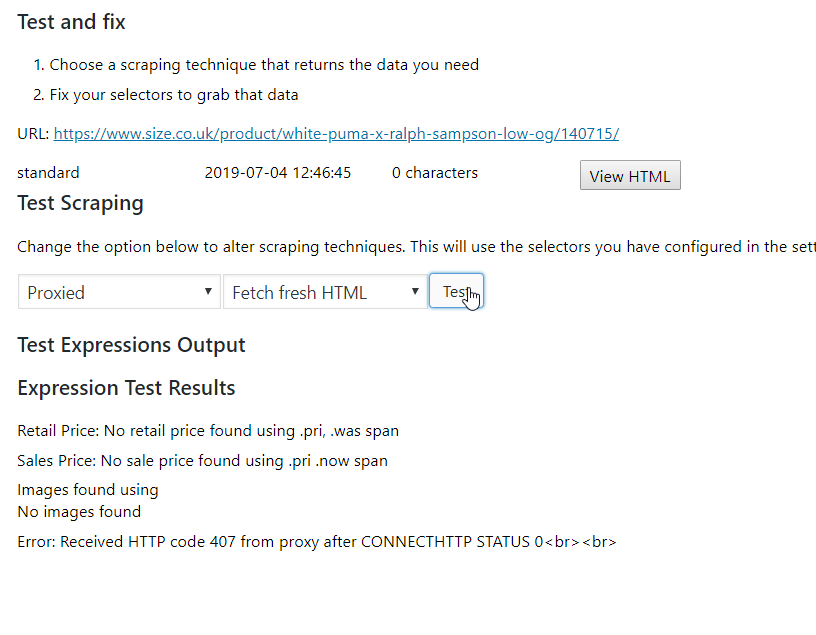
You can see a different error returned above – HTTP status 407. This means that there is a ‘proxy authentication’ issue. In this case, it turns out my proxy details are not correct on the settings page, probably because I was testing these error messages. So, I need to go to Price Comparison Pro settings and update my proxy settings and try again to rule out my server IP being banned.
Testing with Scraper API
The guys over at Scraper API focus exclusively on ensuring their scrapers can get past bot blockers. So – they *should* be able to help here. We know now that this isn’t an Ajax problem, nor is it a blocked IP address issue. That means they’re using some very advanced bot blocking techniques we’ve not seen before. See this result from scraping with the Scraper API:
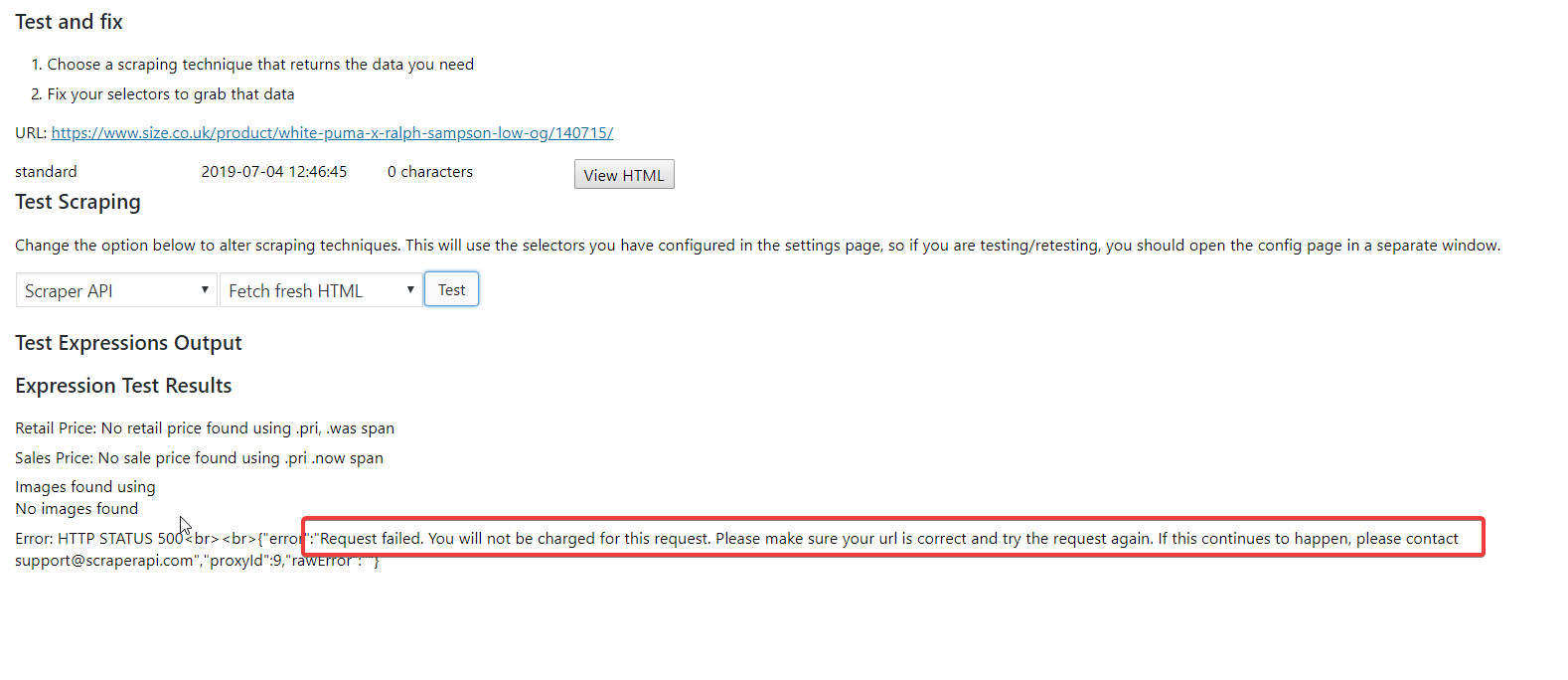
Now – we know that they are not using Ajax to insert prices on the page, but any advanced bot blockers are likely doing some funky stuff involving cookies and redirects to detect non-browsers. So, I’ll try again using the Scraper API rendered approach:
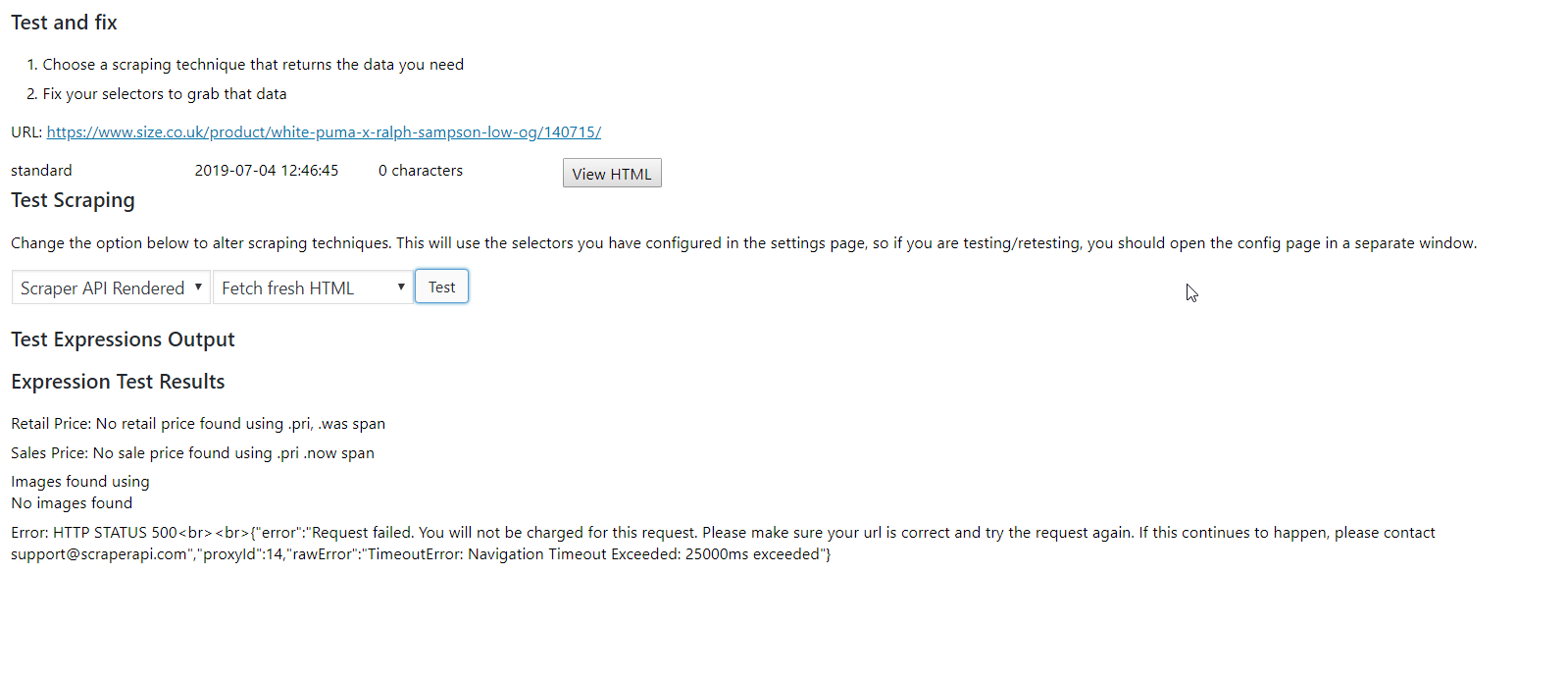
This is not looking good. The error returned is a 500 error – note this is a ‘server error’ but also note because we are using the Scraper API that this 500 error is actually coming from Scraper API servers rather than from the size.co.uk servers.
Just to confirm, I’ll try increasing the timeout in the code for Scraper API requests just in case this makes a difference. It didn’t make a difference.
Testing with other scraping APIs
I’ll keep adding to this list until I find a third-party scraper that will successfully scrape this site, and then I will add an integration to that third-party API directly into the plugin for these rare cases.
RapidAPI – returned a 504 error
Extracty – this returned a more meaningful message – it looks like this size.co.uk site is on the Cloudflare network and they have extreme protection switched on. Getting error 1016.
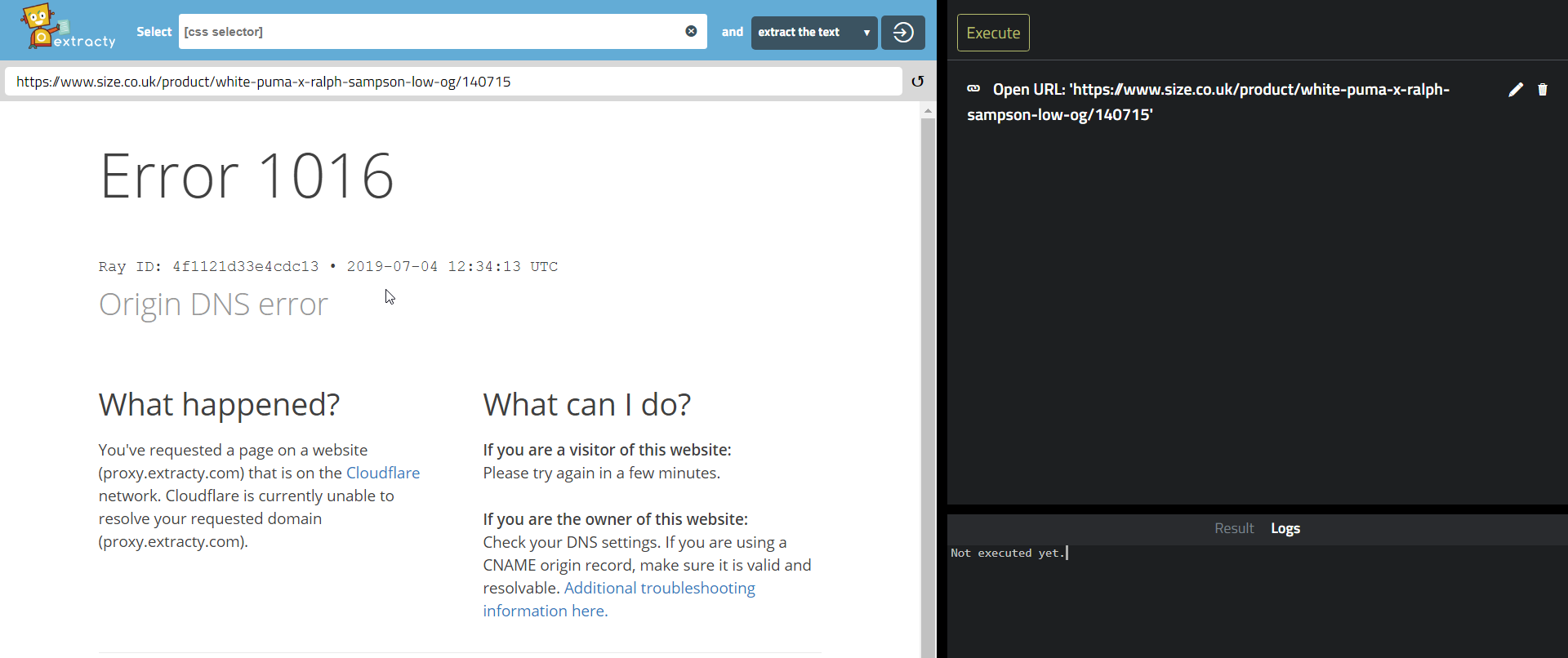
I see the following on stackoverflow for resolving this:
Basically, they are saying to visit the site in your browser, copy all of the cookies, insert them into your scraper config in Price Comparison Pro and then try the ‘standard’ scrape again and it should work.
I tested this and it didn’t help in this case. I’m still investigating for a fix.